
Escrito en ENTRETENIMIENTO el
Actualidad
Adobe se presenta como defensora de los creadores en la era de la IA. Una demanda alega que usó libros con derechos de autor

Adobe ha construido parte de su estrategia en inteligencia artificial sobre una bandera muy reconocible: proteger a los creadores en un momento de cambio profundo. Mientras otras tecnológicas acumulaban críticas por el origen de sus datos, la compañía se presentaba como una alternativa responsable. Esa posición se enfrenta ahora a una demanda que pone el foco en el entrenamiento de uno de sus modelos y en el uso de obras con derechos de autor. El caso no es una anomalía, sino un reflejo de una pregunta que la industria todavía no ha logrado responder con claridad.
La demanda se presentó el martes en el Tribunal Federal del Distrito Norte de California y adopta la forma de una acción colectiva propuesta. Una autora llamada Elizabeth Lyon acusa a Adobe de haber utilizado libros protegidos por derechos de autor, incluidos los suyos, para entrenar modelos de IA de la compañía, con SlimLM como elemento central del caso, sin contar con permiso. Según la documentación judicial, esas obras habrían formado parte del proceso de entrenamiento de sistemas diseñados para responder a instrucciones humanas. Lyon afirma actuar en nombre de otros titulares de derechos que se encontrarían en una situación similar.
El gran debate sobre los datos que entrenan a la IA
Para entender por qué este tipo de litigios se repite cada vez con más frecuencia, conviene detenerse un momento en cómo funciona la inteligencia artificial actual. Más allá de las aplicaciones visibles, desde chatbots hasta generadores de imágenes, existen modelos subyacentes que actúan como el núcleo del sistema y aprenden a partir de enormes volúmenes de datos. En términos generales, disponer de más datos puede mejorar el rendimiento, aunque no es el único factor. El problema aparece cuando surge la pregunta clave sobre el origen de esa información y las condiciones bajo las que se ha utilizado.
El modelo señalado en la demanda no es Firefly, el sistema creativo más conocido de Adobe, sino SlimLM, una familia de modelos de lenguaje de menor tamaño pensada para tareas concretas. Estos modelos están diseñados para asistir a los usuarios en funciones relacionadas con documentos, especialmente en dispositivos móviles. No se trata de una IA orientada a la generación creativa a gran escala, sino de un sistema que opera en segundo plano. Esa diferencia es relevante porque muestra que el debate sobre los datos de entrenamiento no se limita a las aplicaciones más visibles.
Según la demanda, el conflicto no estaría en SlimLM como producto final, sino en los datos empleados durante su fase de entrenamiento. Adobe ha explicado que estos modelos se preentrenaron con SlimPajama-627B, un conjunto de datos de código abierto publicado por Cerebras en junio de 2023. El escrito judicial sostiene que SlimPajama deriva de RedPajama, otro dataset ampliamente utilizado en la industria, y que este a su vez incorpora Books3, una colección masiva de libros protegidos por derechos de autor. Esa cadena es la que, según la demandante, habría permitido la inclusión de obras sin autorización.

Hasta ahora, la narrativa pública de Adobe sobre inteligencia artificial se ha articulado principalmente alrededor de Firefly, un producto claramente identificado con el respeto a los creadores y el uso de contenidos con licencia. La empresa ha defendido que estos modelos se entrenaron con contenido con licencia, como Adobe Stock, y material de dominio público, y ha acompañado ese mensaje con programas de compensación para colaboradores de Adobe Stock. La demanda, sin embargo, no se dirige a ese frente visible, sino, como decimos, a SlimLM, un modelo más discreto, integrado en tareas de asistencia y sin una presencia comercial directa. Esa separación resulta clave para entender el alcance real del caso.
El procedimiento contra Adobe se enmarca en un contexto más amplio de litigios en Estados Unidos relacionados con el entrenamiento de modelos de IA. En los últimos años, autores y otros titulares de derechos han llevado a los tribunales a empresas tecnológicas como OpenAIo Anthropic, con demandas que alegan el uso de obras protegidas sin autorización. Algunos de estos procesos siguen abiertos y otros han terminado en acuerdos millonarios. Ese escenario explica por qué cada nuevo caso se interpreta como un paso más en la delimitación legal del uso de datos en la inteligencia artificial.

Por ahora, el caso se encuentra en una fase inicial y deja abiertas muchas incógnitas. La demandante solicita una compensación económica no especificada y plantea la acción en nombre de otros posibles afectados, mientras que Adobe no respondió a la solicitud de comentarios de Reuters. Será el proceso judicial el que determine si la demanda prospera, se archiva o deriva en un acuerdo. Más allá de su desenlace concreto, el litigio vuelve a poner el foco en una cuestión que sigue sin resolverse del todo: cómo equilibrar el avance de la IA con los derechos de quienes crean los contenidos de los que aprende.
Imágenes | Rubaitul Azad | Adobe
ues de anuncios individuales.
Source link
Continue Reading

Si estás intentando entrar en X (anteriormente Twitter) y todo lo que ves es una pantalla vacía, no estás solo. Desde hace unos 30 minutos, la red social propiedad de Elon Musk ha empezado a dar fallos y no se puede leer ningún post ni desde la web ni desde la app.
Caída generalizada. Downdetector es una de las webs más fiables para saber si un servicio está caído en un momento puntual. Sobre las 14:00 han empezado a reportarse fallos, que rápidamente han ido escalando. Una hora después ya se han alcanzado casi 4.000 reportes sólo en España. Según Techradar, en EEUU se han registrado más de 40.000 reportes y más de 3.000 en Reino Unido, por lo que tampoco parece algo localizado.
23 TRUCOS de TWITTER – ¡Domina por completo esta RED SOCIAL!
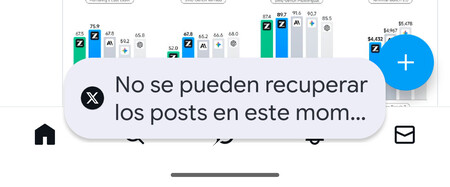
Web y app. El fallo se está produciendo a nivel servicio, es decir que tanto la web como la app están caídas. Si tratas de acceder, es posible que la pantalla se quede en blanco (o en negro si tienes el modo oscuro) o que veas un mensaje tipo “Algo salió mal”. Accediendo desde la app nos aparece el mensaje “No se pueden recuperar los posts en este momento”.
Y ahora qué. Twitter es el sitio donde solemos acudir para estar al tanto cuando ocurre algún evento importante, también cuando caen otros servicios. Recordemos la caída masiva de Facebook y todos sus servicios en 2019, un apagón en el que la propia Facebook usó Twitter para comunicarse con los usuarios. Es una práctica muy habitual. Hace unas semanas caía Spotify y el comunicado también llegó a través de X. ¿Por dónde se comunica X cuando se cae X? No lo sabemos
En desarrollo….
ues de anuncios individuales.
Source link
Actualidad
Pareja de artistas surcoreanos confirma la llegada de su primer hijo tras cuatro años de matrimonio


La exintegrante del grupo de K-pop “9 MUSES“, Lee Keum-jo confirmó que espera a su primer hijo tras haberse casado hace cuatro años con el actor de musicales Baek Ki-bum.
La exidol publicó una fotografía en sus redes sociales junto con su pareja, en donde ambos sostenían el test de embarazo positivo.
En la descripción, la mujer de 33 años de edad destacó que la llegada de su primer hijo no ocurrió de manera sencilla. Mencionó que ambos llevaban desde abril de 2024 tratando de quedar embarazados.
“Justo cuando estaba a punto de darme por vencida, le pregunté a mi padre por primera vez —quien ya falleció— ‘Papá ¿no te arrepientes de dejarme sola? Entonces, por favor, envíame un bebé”, agregó.
En su publicación dijo que el 17 de diciembre, el día de su cumpleaños, se realizó una nueva prueba de embarazo con la que cumplió el anhelo de su corazón: “Recibí dos líneas que lo confirmaban, mi regalo de cumpleaños”, mencionó.
Además de dar a conocer la esperada noticia por los fanáticos de ambos, la intérprete de “Wild” también reveló que su bebé llegará a sus vidas físicamente en agosto.
“A nuestro bebé le pusimos el apodo de ‘Parang-i’ que significa el ‘amor de papá’ y también ha sido mi color favorito durante mucho tiempo”, agregó.
Cabe mencionar que la palabra “parang” en el alfabeto coreano llamado “Hangul” es utilizada para nombrar al color azul.
El grupo veterano de K-pop “9 MUSES” o “Nine Muses” comenzó en el año 2010, aunque ella se integró a partir de 2015; este se disolvió nueve años después debido a que las integrantes ya no desearon renovar sus contratos y continuaron sus respectivas carreras en solitario.
ues de anuncios individuales.
Source link

Durante años teníamos en nuestra mente una narrativa bastante clara de lo que había ocurrido con nuestros antepasados. El relato concreto es que los Homo sapiens salieron de África, se encontraron con unos cuantos neandertales en algún lugar de Oriente Próximo, tuvieron un par de encuentros fortuitos de pulsos de hibridación y siguieron su camino para conquistar el mundo.
Un cambio. Sin embargo, un nuevo estudio masivo que acaba de aparecer en el servidor de preimpresión bioRxiv sugiere que esa imagen es demasiado simplista. No fueron encuentros puntuales, sino que fue una interacción continua a lo largo de una inmensa “zona híbrida” que abarcó desde el Próximo Oriente hasta Asia Central y Europa.
Para llegar hasta aquí, el estudio ha analizado una cantidad sin precedentes de ADN antiguo para dibujar el mapa más detallado hasta la fecha de cómo nos mezclamos con nuestros primos extintos. Y el resultado es un gradiente de mestizaje que se extiende por casi 4.000 kilómetros.

Mucho volumen. El estudio no se ha limitado a unos pocos huesos que se hayan encontrado de manera aislada, sino que han utilizado simulaciones informáticas y un conjunto de datos de 1.264 de paleogenomas. Algo que corresponde a miles de individuos con una antigüedad superior a los 10.000 años.
Su conclusión. Los patrones de ADN neandertal que llevamos hoy en día en nuestro material genético no se explican bien con modelos de “pulsos aislados”, sino que la simetría encontrada entre los genomas de Europa y Asia indica que hubo un contacto prolongado.
De esta manera, a medida que los humanos modernos se expandían fuera de África, que es lo que conocemos como Out of África, hace unos 60.000 años, fueron empujando una frontera demográfica. En ese frente de avance, el flujo génico fue moderado pero constante. Es por ello que no fue un evento de un día, sino un proceso geográfico largo.
El cómo. Para entender esto hay que mirar estudios complementarios que apuntan a que la clave está en los gradientes espaciales. Para visualizar el concepto, podemos imaginar una ola que avanza como si fueran los sapiens que se iban moviendo y encontrándose con los neandertales. Pero la clave es que la ascendencia neandertal no es uniforme.
Esto quiere decir que los primeros sapiens en Europa contaban con un nivel alto de ADN neandertal, pero posteriores expansiones, como la llegada de los agricultores neolíticos desde Anatolia, “aguaron” esa herencia neandertal, especialmente en Europa, creando una diferencia notable con las poblaciones de Asia. Aquí es donde el estudio presentado en este 2026 confirma que solo un modelo de expansión persistente con flujo génico puede explicar por qué encontramos señales de mestizaje a casi 4.000 km del punto de origen en el Próximo Oriente.
¿Cuándo ocurrió? Aquí es donde la cosa se pone interesante al cruzar los datos con otros estudios recientes, como el publicado en Nature en 2024. Y es que aunque la zona fue amplia, la ventana de tiempo fue crítica.
El análisis de más de 300 genomas humanos tempranos apunta a una “ventana única” de hibridación principal hace entre 47.000 y 43.000 años. Esto excluye teorías anteriores que sugerían múltiples pulsos muy antiguos. Y para ir un poco más allá, hubo un momento, cuando nuestra especie estaba asegurando su dominio en Eurasia, en el que la barrera entre especies se difuminó en una franja geográfica enorme.

Un mapa de interacciones. Lo que sugiere este cuerpo de investigación es que la zona híbrida abarca casi todos los yacimientos neandertales conocidos como Eurasia occidental, por lo que implica interacciones geográficamente extensas.
No obstante, como suele ocurrir en ciencia, hay que mantener la cautela. Este estudio aún tiene que pasar una revisión completa y tiene limitaciones al basarse en supuestos demográficos y que no modela la selección natural que tenemos en el mundo genético. Aun así, la imagen es cada vez más nítida: no somos el resultado de una especie que reemplazó a otra de golpe. Somos, en parte, el resultado de una larga frontera de contacto donde, durante milenios, la línea entre “ellos” y “nosotros” fue mucho más borrosa de lo que creíamos.
Imágenes | Marc Tremblay
ues de anuncios individuales.
Source link
-

 Actualidad1 día ago
Actualidad1 día agoLa carrera más salvaje en las pistas olímpicas de Cortina fue en 1981. Un hombre se lanzó esquivando balas y asesinos en motocicleta
-

 Actualidad1 día ago
Actualidad1 día agoel deporte se ha disfrazado de terapia para cobrarte más dinero
-

 Cine y Tv19 horas ago
Cine y Tv19 horas agoConoce los nuevos incentivos para la industria de cine en México
-

 Actualidad21 horas ago
Actualidad21 horas agoHay gente compartiendo con la IA sus casos judiciales. El problema es cuando un juez considera como pruebas las conversaciones
-

 Tecnologia2 días ago
Tecnologia2 días agoExpertos de UNAM buscan en el río Querétaro bacterias con resistencia antimicrobiana
-

 Musica2 días ago
Musica2 días agoRosalía cantará en la gala de los Brit Awards 2026
-

 Actualidad2 días ago
Actualidad2 días agoLos países están intentando evitar la acumulación de riqueza de los millonarios tecnológicos. La Antigua Roma también lo intentó
-

 Actualidad1 día ago
Actualidad1 día agolos bloqueadores de anuncios siguen ahí