
Escrito en ENTRETENIMIENTO el
Actualidad
hacerla tan barata que sea “invisible” para el usuario

DeepSeek es la punta de lanza cuando hablamos de inteligencia artificial de China. No sólo cuenta con un gran rendimiento, sino que la propia Microsoft ha dado la voz de alarma al apuntar que su política está permitiendo que gane usuarios en mercados en los que otros como OpenAI lo tienen más difícil. Otras empresas como Tencent o Alibaba están dando pasos de gigante en la lucha por la IA, y hace unos días ByteDance –TikTok– presentó un Seedance 2.0 que es impresionante… y ya le está trayendo dolores de cabeza.
Pero los grandes no son los únicos, y con una China volcada en el desarrollo de la robótica y la IA, hay que hablar de otros ‘jugadores’ más pequeños. Zhipu AI y MiniMax son dos de los “tigres” que, en apenas unos años, han levantado cientos de millones de dólares y que cuentan con modelos que tienen una filosofía radicalmente distinta a la de OpenAI y otros gigantes occidentales.
Sus modelos se venden como compañeros de vida, herramientas que la gente pueda usar en el día a día sin preocuparse por el precio. Y, dentro de ese discurso, MiniMax acaba de lanzar el M2.5, un modelo que quiere convertirse en un “empleado digital” y que sus responsables han catalogado como su primer “modelo de frontera” tan barato que no vale la pena medir el precio.

Una IA demasiado barata como para preocuparse por el precio
M2.5 ya es oficial y, como recoge South China Morning Post, MiniMax no ha querido desperdiciar la oportunidad de lanzarlo en una semana frenética para la industria de la IA en China. Técnicamente, M2.5 es un LLM -gran modelo de lenguaje- que puede con unos 230.000 millones de parámetros totales, pero sólo utiliza 10.000 millones por token. Al ser un sistema Mixture of Experts, cada llamada sólo implica a los expertos directamente necesarios para resolver la petición.
Bajando a tierra la cifra, eso significa que es un modelo capaz, pero por petición de usuario no utiliza todo su potencial, lo que implica bajos costes de inferencia y precios muy bajos para los usuarios. Sus responsables afirman que el precio es de apenas un dólar por hora de funcionamiento continuo, gastando 100 tokens por segundo. Esto significa que puedes tener un “agente” trabajando de manera continua durante todo ese tiempo a un precio entre 10 y 20 veces más bajo que otros modelos como Opus, Gemini 3 Pro o GPT-5.
Esa política tan agresiva hace que M2.5 sea un modelo “demasiado barato como para cuantificarlo”, según sus responsables, facilitando esa adopción masiva porque el usuario puede dejar de optimizar cada orden que da a la IA. Esa frase de “too cheap to meter” es un guiño al histórico comentario en el que se apuntaba que la electricidad procedente de la energía nuclear sería demasiado barata como para medirla.
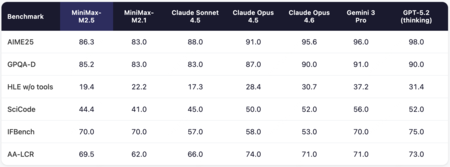
Puntuación interna en diferentes pruebas | Imagen: MiniMax
Y algo importante es que M2.5 no es un simple chatbot. Está disponible en plataformas como Ollama, HuggingFace, ModelScope en China o GitHub, y la propia MiniMax apunta que el 30% de las tareas internas de la compañía ya las realiza el propio M2.5. Además, el 80% del código nuevo es generado por el modelo. Es decir, está más optimizado para trabajar solo que para chatear. Esto del código creado por código no es exclusivo de M2.5, y Codex y Opus también está en este barco.
El modelo ya ha sido puesto a prueba y, si bien en algunas tareas consigue resultados notables, sobre todo comparado con otros modelos open-weight, su puntuación dista de la de los modelos cerrados. En los resultados internos de la propia compañía, consiguió doblar la puntuación del modelo anterior, el M2.1, pero como bien apunta SCMP, estas puntuaciones de referencia internas son complicadas de verificar de forma independiente.
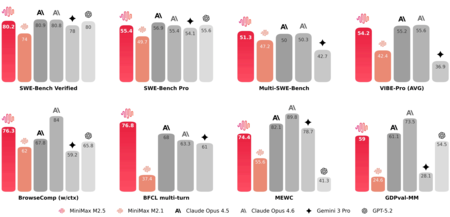
Benchmark interno en coding | Imagen: MiniMax
Pero, al final, sea más o menos capaz en comparación con otros modelos, MiniMax M2.5 es un ejemplo más de la estrategia que está empujando China con la inteligencia artificial. Mientras Estados Unidos se está esforzando en demostrar que tiene modelos propietarios cada vez más potentes y capaces, IA está en una narrativa en la que pretende impulsar modelos más baratos y útiles para el usuario.
Esto implica no sólo que tengan una buena relación prestaciones/precio, sino también que puedan ejecutarse en dispositivos del día a día sin una enorme capacidad de cálculo. Y ahora que, supuestamente, ciertas empresas chinas podrán hacerse con algunas de las mejores GPU de NVIDIA para entrenar a la IA, el impulso a esa estrategia puede ser notable.
Imágenes | MiniMax (editada)
ues de anuncios individuales.
Source link
Continue Reading
Actualidad
Matty Healy, vocalista de “The 1975” y la modelo Gabbriette se casan en una antigua propiedad de Madonna


Matty Healy y Gabriette Bechtel han caminado juntos al altar donde dijeron “sí” al oficializar su unión con el matrimonio tras haber sido novios durante nueve meses, este sábado.
El cantante británico de la banda The 1975 de 37 años de edad reveló en 2024 su noviazgo con la modelo estadounidense de 28 años de edad y tras casi 10 meses de relación, la pareja se comprometió en una ceremonia privada celebrada en Los Ángeles.
El dúo de diseñadores originarios de Canadá, Matières Fécales, fueron los encargados del vestido de novia que portó la también vocalista y compositora de la banda de rock, Nasty Cherry, el vestido es de color blanco y estilo gótico con una apertura completa en la espalda cubierta con listones.
Según los medios especializados, los representantes de ambas figuras indicaron que la ceremonia fue privada y que la pareja estuvo acompañada por sus amigos y familiares más cercanos, esta fue celebrada en el Castillo del Lago, antigua propiedad de Madonna en Hollywood Hills.

Entre los asistentes cuyos nombres forman parte de la farándula se encuentran: Charlie XCX quien asistió con su esposo, George Daniel, quien además es también integrante de The 1975, Anastasia Karanikolau, Fai Khadra, Alex Consani, Devon Lee Carlson, Sydney Lynn Carlson, Tyrell Hampton, Alex O´Connor y Quenlin Blackwell.
Antes de que Matty Healy y Gabriette Bechtel celebraran nupcias, cada uno festejó sus despedidas de soltero, Healy convivó con sus amigos y una banda tributo de su propio grupo según reveló una página de fans en redes sociales quienes interpretaron “The Sound”, juntos.
Trascendió en redes sociales una serie de fotografías en las que los ahora esposos se encuentran tomándose fotografías y videos, uno de los momentos que conmocionó más a los seguidores fue cuando la pareja compartió un beso en lo que pareciera ser la entrada de la recepción.
Hasta el momento ambas personalidades no han hecho alguna publicación oficial tras haberse unido en matrimonio.
ues de anuncios individuales.
Source link

Las olas de calor extremo son un desafío estructural cada vez más intenso y duradero y, ante unas ciudades convertidas en trampas de asfalto con una clara falta de árboles, el concepto de “refugio climático urbano” ha ganado fuerza como infraestructura de emergencia. Sin embargo, no cualquier espacio verde actúa como escudo térmico, puesto que una reciente investigación liderada por la Universidad de Granada evidencia que el diseño, la morfología y, sobre todo, el tipo de arbolado son factores críticos, puesto que un área verde sin una densa cobertura pierde casi toda su eficacia de reducir la temperatura.
El tamaño no lo es todo. Los primeros resultados del proyecto ACTERCA, liderado por el investigador David Hidalgo de la UGR, muestran el comportamiento térmico de las zonas verdes en las ocho capitales andaluzas. Para llevarlo a cabo, utilizaron una combinación de satélites, modelización climática, inteligencia artificial y cámaras térmicas, y la investigación concluye que la capacidad de enfriamiento depende críticamente de los árboles de gran porte y copa densa.
Estos árboles concretos son los que de verdad consiguen reducir la temperatura ambiental entre 3 y 5 ºC en comparación con las zonas dominadas por pavimentos impermeables o el clásico albero. Es por ello que la clave no está en crear refugios climáticos “que se vean verdes”, sino en diseñarlos específicamente para que ofrezcan una buena sombra y evapotranspiración con los árboles más adecuados. Se explica de la siguiente manera por parte de la UGR:
Estos procesos reducen la temperatura ambiental y mejoran significativamente el confort térmico de quienes utilizan estos espacios. Por el contrario, las zonas verdes con escasa cobertura arbórea pierden gran parte de su capacidad para amortiguar el calor, lo que pone de manifiesto que aumentar la superficie verde, por sí solo, no garantiza una protección efectiva frente a las olas de calor.

Es personalizado. El estudio también subraya que el diseño urbano no admite recetas universales, puesto que en ciudades como Sevilla y Málaga, el problema principal reside en el albedo y en Córdoba, la amenaza es la densidad edificatoria y la impermeabilización del suelo. Pero si nos vamos a Granada, la geometría de los barrios históricos, con calles angostas, ofrece una resiliencia térmica superior a la de los nuevos desarrollos urbanísticos.
Más allá de la temperatura. Si bien la bajada del termómetro es el objetivo más visible, ciencia advierte que el concepto de “refugio climático urbano” aún está en pañales y su definición carece de consenso. Según una revisión sistemática, el urbanismo actual se está centrando casi en exclusiva en el confort térmico, dejando inexplorado el potencial de estos espacios para fomentar la biodiversidad urbana o la mitigación climática a largo plazo.
De hecho, se apunta que los refugios climáticos deben concebirse como soluciones multiescalares, puesto que no basta con una plaza aislada, sino que es necesaria una red interconectada. En esta línea, la ciencia propone metodologías específicas (probadas en Sevilla y Málaga) para diseñar redes de refugios que clasifiquen los espacios según su uso: lugares de alivio temporal, áreas para la actividad cotidiana o zonas de asistencia crítica durante desastres.
El verdadero reto. El mayor obstáculo al que se enfrentan los refugios climáticos no es termodinámico, sino social. Y se que de nada sirve un parque excelentemente climatizado si quienes más sufren el calor no pueden acceder a él o no se sienten integrados.
Por ejemplo, un análisis en el IERMB sobre la red de refugios de Barcelona demostró que existen profundas vulnerabilidades interseccionales, puesto que factores como los ingresos económicos, el género y el origen cultural determinan quién usa realmente estos espacios. Esta desigualdad geográfica y de renta también es denunciada por Greenpeace España, cuyo informe alerta de una grave desprotección frente a las olas de calor en los sectores más vulnerables de la población, abordando el acceso al confort térmico como un derecho fundamental.

Vamos atrasados. Sabemos qué funciona y cómo implementarlo, pero la administración sigue yendo un paso por detrás. Una revisión a nivel europeo que analizó 97 iniciativas en 88 ciudades desveló una notable desconexión institucional, puesto que las estrategias nacionales de adaptación climática rara vez se integran verticalmente con las prácticas locales.
Los planes redactados sobre el papel tardan demasiado en convertirse en árboles plantados en el asfalto. Y el mensaje que tenemos encima de la mesa es que, para combatir el calor extremo de las próximas décadas, las ciudades no necesitan simplemente más metros cuadrados pintados de verde en un plano, sino ecosistemas urbanos densamente arbolados, inteligentemente distribuidos y, sobre todo, socialmente justos.
Imágenes | Andy Lee
ues de anuncios individuales.
Source link
Actualidad
“La Odisea” debuta en la pantalla grande con más de 250 mdd de recaudación a nivel mundial

AP.- “La Odisea”, de Christopher Nolan, se estrenó con una recaudación estimada de 124.5 millones de dólares en ventas de entradas en el mercado norteamericano y otros 139.6 millones en el extranjero, lo que supone un debut aún mejor que el de “Oppenheimer” y marca el mejor arranque del cineasta desde “The Dark Knight Rises” de 2012.
Christopher Nolan exhibió su singular poder en la taquilla con un debut global como ningún otro.
Pocos cineastas vivos podrían sacar adelante una adaptación de gran presupuesto y con un reparto estelar del poema épico de Homero. Pero en un Hollywood donde los derechos de propiedad intelectual dominan la mayoría de los éxitos, Nolan convirtió una de las obras literarias más antiguas del mundo en un improbable taquillazo veraniego.
La producción de Universal no fue una apuesta menor por Nolan, que venía de “Oppenheimer”, ganadora del Oscar a mejor película en 2023. Con un presupuesto de producción de 250 millones de dólares, está entre las películas con clasificación R más caras jamás realizadas. Universal está gastando unos 125 millones de dólares en su promoción.
Pero ningún nombre detrás de la cámara atrae al público más que el de Nolan. Fue tal la expectación por “La Odisea” que IMAX puso a la venta entradas para algunas funciones en 70 mm con un año completo de antelación. Para satisfacer la extraordinaria demanda del formato preferido de Nolan, IMAX 70 mm, algunos cines añadieron proyecciones a medianoche y a las 3:00 de la madrugada, y se agotaron.
“Es increíblemente gratificante ver la emoción palpable en los cines este fin de semana”, dijo Jim Orr, responsable de distribución nacional de Universal. “Nolan ha creado una aventura épica. Tiene una escala a la que el público ha respondido extraordinariamente bien”.
IMAX impulsa la venta de boletos
Anunciada como el primer largometraje de Christopher Nolan rodado íntegramente con cámaras IMAX, el formato impulsó una enorme porción de las ventas de entradas. Eso incluyó 29.6 millones de dólares en el mercado nacional en IMAX y 51.8 millones a nivel mundial, lo que llevó a la compañía a su mejor fin de semana de la historia.
IMAX dedicará sus pantallas por completo a “La Odisea” durante tres semanas. Aunque solo 41 pantallas IMAX pueden proyectarla en 70 mm, representaron 6.3 millones de dólares en ventas de entradas.
Rich Gelfond, director ejecutivo de IMAX, comentó: “Todo lo relacionado con IMAX ayudó a convertirla no solo en un éxito de taquilla, sino en un acontecimiento cultural global. Tenemos entradas a la venta para la quinta semana en algunos cines y algunas de esas funciones ya se han agotado”.
Desde la pandemia, el cineasta ha estado a la vanguardia de la reactivación de las salas. Su “Tenet” fue uno de los primeros grandes estrenos en volver a los cines en 2020. Tres años después, “Oppenheimer” y “Barbie”, de Greta Gerwig, se combinaron para crear, posiblemente, el momento cinematográfico emblemático de la década. “Oppenheimer” terminó recaudando 975 millones de dólares en todo el mundo.
“La Odisea” llegó a los cines durante el mejor verano de Hollywood desde 2019. Las ventas de entradas aumentaron un 10.4% respecto del año pasado, según Rentrak. La industria espera el primer año de 10 mil millones de dólares en la taquilla nacional desde la pandemia.
“La Odisea” podría mantenerse hasta el otoño
La única pregunta para “La Odisea” será cuánto dependerá de su primer impulso, dado que muchos cinéfilos tenían este fin de semana marcado desde hace meses. La película no enfrentó competencia de más estrenos este fin de semana ni el próximo.
Gelfond señaló que las preventas para el segundo fin de semana de la película se ubicarían entre sus 10 mejores preventas, prueba de que muchos espectadores están esperando verla en su formato preferido. Las funciones en IMAX 70 mm, añadió, están en gran medida agotadas para el próximo mes, salvo algunos asientos de la primera fila.
Paul Dergarabedian, responsable de tendencias del mercado en Rentrak, manifestó: “Christopher Nolan y Tom Cruise pueden ser los dos embajadores de más alto perfil de la experiencia de la gran pantalla. Nolan es un director que es una estrella tanto como cualquier estrella de cine delante de la cámara”.
El público de la nueva película de Nolan fue notablemente masculino, al representar el 59% de las entradas vendidas. Pero Orr sostuvo que, por lo demás, los asistentes fueron “ridículamente amplios”, con presencia en distintos grupos demográficos y regiones.
“Está funcionando para un chico de 17 años de edad y está funcionando para una mujer de 55 años de edad o más”, según Orr. “Eso apunta a lo que estoy convencido de que será una permanencia muy larga y muy exitosa no solo durante el resto del verano, sino también hasta el otoño”.
La próxima película que supondrá alguna competencia, irónicamente, también está protagonizada por Tom Holland y Zendaya: “Spider-Man: Brand New Day”, de Sony, el 31 de julio.
La controversia por el reparto no parece tener efecto
“La Odisea” está protagonizada por Matt Damon como Odiseo y cuenta con Holland como su hijo, Telémaco; Anne Hathaway como Penélope; Zendaya como Atenea; Robert Pattinson como el pretendiente Antínoo y Charlize Theron como la ninfa marina Calipso.
El reparto elegido por Nolan, que incluye a Lupita Nyong’o como Helena y a Elliot Page como un soldado, fue controvertido para algunos comentaristas conservadores. Elon Musk calificó a Nolan de “cobarde” por elegir a Nyong’o.
Pero esas críticas tuvieron poco o ningún efecto en que la película se convirtiera en uno de los acontecimientos culturales del año en la gran pantalla. Las reseñas (95% positivas en Rotten Tomatoes) están entre las mejores de la carrera de Nolan. El público le otorgó una “A” en CinemaScore.
Las películas con clasificación PG siguieron la estela de “La Odisea”.
“Moana”, de The Walt Disney Co., quedó en un lejano segundo lugar con 19 millones de dólares en su tercer fin de semana. Tras su decepcionante estreno de 43 millones de dólares, el remake de acción real cayó 56% en su segundo fin de semana. En dos semanas recaudó 178 millones de dólares en todo el mundo, un mal resultado para una película que costó 250 millones de dólares producir.
A “Moana” le siguieron “Minions & Monsters”, de Universal, y “Toy Story 5”, de Disney, ambas con una recaudación de alrededor de 15 millones de dólares.
ues de anuncios individuales.
Source link
-

 Actualidad2 días ago
Actualidad2 días agohace más de 2.000 años ya los usaban en Grecia
-
 Actualidad21 horas ago
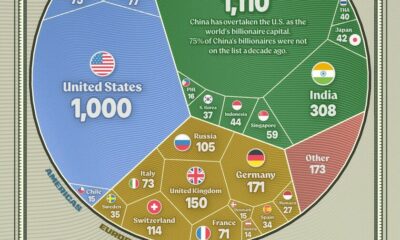
Actualidad21 horas agoLos países con más multimillonarios del mundo, reunidos en un gráfico con un sorprendente ganador
-
Actualidad21 horas ago
Los países con más multimillonarios del mundo, reunidos en un gráfico con un sorprendente ganador
-
Musica1 día ago
Aleks Syntek reinventa “Bendito Tu Corazón” con una fusión de cumbia pop
-

 Actualidad1 día ago
Actualidad1 día agoÓscar Maydon en entrevista, intento de robo a Lamine y Tom Cruise ¡Irreconocible!
-

 Musica21 horas ago
Musica21 horas agoParacho: un viaje al corazón de la tradición purépecha
-

 Actualidad1 día ago
Actualidad1 día agoArrestan en Miami a los influencers Andrew y Tristan Tate; ambos enfrentan denuncias por presunta violación
-

 Actualidad1 día ago
Actualidad1 día agoLlevamos años escuchando que los adultos no tienen que beber leche. Los últimos estudios dicen todo lo contrario

