
Actualidad
su CEO acaba de aclarar quién debe tener los mejores

La carrera por la inteligencia artificial suele contarse desde los modelos, las aplicaciones y las últimas promesas de automatización. Pero debajo de todo eso hay una capa menos vistosa y mucho más difícil de sustituir: el hardware. Sin chips avanzados, entrenar modelos masivos, desplegarlos a gran escala y competir en la primera línea se vuelve mucho más difícil. Por eso NVIDIA sigue ocupando un lugar tan importante para Estados Unidos y para China. La cuestión ya no es solo quién desarrolla mejor IA, sino quién puede acceder primero a los chips más potentes.
El mensaje de Huang. Ese debate aterrizó esta semana en Los Ángeles, durante la Milken Institute Global Conference, un foro que reunió a banqueros, inversores, responsables políticos y ejecutivos en Beverly Hills. Allí, según Nikkei Asia, Jensen Huang fue preguntado directamente por una cuestión especialmente sensible: si China debería tener acceso a los chips “más recientes y mejores” de NVIDIA. Su respuesta fue tan breve como contundente: “No”. El CEO añadió después que la compañía apoya que Estados Unidos tenga “los primeros, más y mejores” chips, una frase que resume bastante bien el equilibrio que intenta defender.
Vender sí, pero no lo último. La posición de Huang no pasa por sacar a China de la ecuación comercial, al menos no según lo que planteó en ese mismo foro. El CEO defendió que las compañías estadounidenses de semiconductores sigan compitiendo en los mercados globales, incluido el chino, porque eso también fortalece al país norteamericano. Huang sostuvo que aumentar las exportaciones ayuda a elevar la recaudación fiscal, mejorar la seguridad económica y contribuir a la seguridad nacional. El mensaje, por tanto, tiene dos capas: liderazgo tecnológico primero, y presencia comercial bajo control después.
La frontera está en la generación. No todos los chips de NVIDIA ocupan el mismo lugar en esta discusión. El H200, recordemos, es un procesador de IA de gama alta y lo coloca por encima del H20, el chip que la compañía diseñó para China tras las restricciones de exportación estadounidenses. Pero el acuerdo anunciado por Donald Trump en diciembre no incluía ni Blackwell ni los productos Rubin de próxima generación, dos familias que representan una capa más avanzada de la hoja de ruta de NVIDIA.
El encaje regulatorio todavía tiene varias piezas móviles. Donald Trump dijo en diciembre que permitiría vender los H200 de NVIDIA a clientes “aprobados” en China, siempre que el Gobierno estadounidense recibiera un 25% de esos ingresos. La compañía obtuvo este año la autorización oficial de exportación, y Huang aseguró en marzo que NVIDIA ya había recibido pedidos de “muchos clientes” chinos. Pero eso no significa que todo esté resuelto: el envío final también dependerá de si Pekín permite esas ventas y en qué cantidades.

El cuello de botella no es solo político.Tom’s Hardware sugiere que también puede haber una explicación industrial detrás de la ausencia de envíos recientes. Según el medio, Hopper y Blackwell se fabrican en las mismas fábricas y líneas de producción compatibles con N4/N5 de TSMC, una capacidad que no es infinita. Si esa lectura es correcta, NVIDIA tendría motivos para reservar más producción para Blackwell, una familia más avanzada y cara, especialmente para clientes estadounidenses, en lugar de usar parte de esa capacidad en H200 para China con una comisión del 25% al Gobierno de EEUU. Según esa lectura, la llegada de Rubin en N3 podría liberar margen más adelante.
Un viaje pendiente. Trump dijo que visitará Pekín este mes y que las cuestiones comerciales podrían estar sobre la mesa en su encuentro con Xi Jinping. En ese contexto, las palabras de Huang no suenan como una simple reflexión corporativa, sino como una forma de marcar posición en un debate que va mucho más allá de NVIDIA. La disputa no gira solo alrededor de qué chip es más potente, sino de quién accede primero, bajo qué condiciones y con qué margen para no quedarse atrás.
Imágenes | NVIDIA + Xataka con Photoshop
ues de anuncios individuales.
Source link
Actualidad
Vevo estaba en todos los videoclips de internet en los 2000s. Hoy es solo otro episodio olvidado de la vieja industria musical

En diciembre de 2009, dos de los mayores sellos discográficos del planeta organizaron una fiesta en Nueva York con Bono como invitado de honor para celebrar el lanzamiento de algo que, según ellos, iba a devolverles el control del negocio musical en internet, que como ahora veremos, no pasaba por su mejor momento. Se llamaba Vevo, acrónimo de “Video Evolution”. La (r)evolución duró menos de una década: los cambios de raíz en el negocio y la llegada de una forma distinta de entender los vídeos musicales lo relegó al plano secundario de nostalgia para millennials que es hoy.
Malos tiempos. A finales de los 2000, la industria musical se estaba resquebrajando. Los ingresos por venta de discos llevaban años cayendo por el efecto combinado de la piratería y una digitalización caótica, a espaldas de los sellos, y que estaba muy lejos del momento ordenado y oficial que vive hoy gracias a las plataformas de streaming. Por ejemplo: YouTube (que ya había sido comprado por Google en 2006) acumulaba cientos de millones de reproducciones de videoclips sin que los sellos vieran ni un euro de compensación. Se intentaron renegociar los términos de esa relación, sin éxito: Warner Music fue la primera en retirar su catálogo completo de YouTube en 2008.
Ideaca. Doug Morris, entonces CEO de Universal Music Group y figura central en la creación de Vevo, visualizó una forma de entrar en el negocio de internet y los videoclips cuando vio a su nieto consumiendo videoclips online con publicidad, lo que le llevó a preguntar cuánto dinero estaba generando Universal con esas reproducciones… La respuesta era obvia: cero. A partir de ese momento, Morris presionó a empresas como Yahoo y MTV para que le compensaran por reproducir su vídeos. Él sí acabó llegando a un acuerdo con Google.

Q: Are We Not Men? A: We Are Vevo! Vevo se lanzó oficialmente el 8 de diciembre de 2009 tras un acuerdo entre Universal Music Group, Sony Music Entertainment y EMI, con Warner Music Group sumándose años después, en agosto de 2016. Vevo aportaría el catálogo oficial en alta definición, YouTube serviría como plataforma de distribución masiva, y ambas partes venderían publicidad sobre ese inventario. En octubre de 2009, la Abu Dhabi Media Company ya había invertido unos 300 millones de dólares para operar en Estados Unidos y Canadá.
¿Resultado inmediato? Espectacular. En su primer mes ya era el sitio de música más visitado de Estados Unidos, superando a Myspace Music. El impacto económico también fue rápido: según el CEO de Vevo de entonces, el CPM medio de un vídeo musical online pasó de 3 dólares antes del lanzamiento a más de 30 dólares en 2013. En 2012, Vevo acumulaba 41.000 millones de reproducciones anuales en toda su red, con un catálogo que rondaba los 75.000 vídeos. En agosto de 2013, Vevo había superado a MTV en términos de audiencia digital: 609 millones de reproducciones de vídeo frente a las 261 millones de MTV ese mes. El Vevo Certified para artistas que superaban los 100 millones de reproducciones se convirtió en un indicador de relevancia cultural comparable a un número uno en listas de ventas.
Problemas. Sin embargo, el problema estructural de Vevo no era la audiencia, sino su modelo de reparto. Aunque la compañía facturó 250 millones de dólares en 2013, más del 90% de esos ingresos se repartían entre los sellos, Google y los editores musicales. Universal y Sony capturaban el 55% del total y Vevo operaba en pérdidas. Era, en la práctica, un gestor de inventario publicitario sin capital propio: generaba valor para sus accionistas, los sellos y Google, pero no para sí misma como entidad operativa independiente. En 2014 la compañía contrató a Goldman Sachs y The Raine Group para buscar un comprador que estuviera dispuesto a pagar cerca de 1.000 millones de dólares por la empresa. No apareció ninguno. Vevo descartó la venta y anunció que buscaría la rentabilidad por sus propios medios.
Cambio de rumbo. En abril de 2015 llegó Erik Huggers (creador del famoso iPlayer de la BBC) como nuevo CEO. Vevo quiso entonces construir sus propias aplicaciones para móvil y televisión conectada, reducir su dependencia de YouTube y eventualmente lanzar un servicio de suscripción de pago. Comenzaron a desarrollar apps para iOS, Android y plataformas de TV conectada, pero duró poco: el proyecto de suscripción de pago se canceló en febrero de 2017, y Huggers abandonó el cargo. Se sucedieron dimensiones y despidos y acabó la apuesta por la autonomía tecnológica.
Golpe de gracia. En enero de 2018, YouTube migró automáticamente los suscriptores de los canales con marca Vevo (tipo “RihannaVEVO” o “JustinBieberVEVO”) a los nuevos Official Artist Channels de la misma YouTube. Esa misma semana, YouTube relanzaba YouTube Music como servicio de suscripción de pago, compitiendo directamente donde Vevo había intentado entrar. Paradójicamente, Vevo había logrado el equilibrio contable ese año por primera vez. Pero el modelo propietario nunca había cuajado, y sin él, no había razón para mantener la infraestructura.
Lo que queda de Vevo. Vevo no se ha esfumado completamente, como otros proyectos de la época. La compañía pivotó hacia el negocio de televisión conectada y los canales FAST, los lineales gratuitos con publicidad. Su biblioteca supera los 900.000 videoclips y genera aproximadamente 25.000 millones de reproducciones mensuales. El modelo es, irónicamente, el que MTV nunca consiguió que cuajara: una cadena de música gratuita financiada por publicidad, aunque en el caso de Vevo, distribuida por internet en lugar del cable.
La huella de Vevo no es absolutamente negativa:estableció el estándar del vídeo musical oficial en alta definición en YouTube, creó la infraestructura de monetización que permitió que los videoclips volvieran a ser un negocio, y demostró que la industria discográfica podía negociar de igual a igual con las plataformas tecnológicas. Pero que los videoclips hayan acabado convertidos en coreografías amateur en TikTok es algo que, desde luego, el CEO de Universal no podía prever.
ues de anuncios individuales.
Source link
Actualidad
Cada vez buscamos más respuestas humanas en Reddit. Esa es la razón de que ahora el buscador de Google sea un Reddit disfrazado

Google ha actualizado su plataforma de búsquedas por enésima vez, pero lo ha hecho con un cambio especialmente significativo. La experiencia de usuario en sus buscadores con IA (tanto AI Overviews como AI Mode) intenta volverse más “humana”. Y para ello en esas búsquedas Google añadirá más contexto a los enlaces, como extractos de foros y blogs de internet. Y si hay un beneficiado (o perjudicado) de ese movimiento, ese es Reddit.
Google ya era una pasarela a Reddit. Hay un comportamiento que Google lleva años viendo en sus datos y que durante mucho tiempo prefirió no reconocer públicamente: cuando alguien quiere una respuesta real a una pregunta real, añade “Reddit” al final de la búsqueda. No porque Reddit sea una fuente necesariamente fiable, sino porque en Reddit se reúnen personas reales que han vivido esa cuestión, la han intentado resolver y han escrito sobre ello sin que nadie les pagara por hacerlo. Google, con toda su infraestructura y todos sus algoritmos, no había conseguido replicar eso. Así que en lugar de intentarlo va a incorporar esas respuestas directamente.

Qué ha cambiado exactamente. La actualización del buscador hará que en los AI Overviews aparezcan fragmentos de foros, redes sociales y otras “fuentes de primera persona”. Cuando alguien busque algo para lo que no existe una respuesta objetiva única, la IA de Google incluirá perspectivas y opiniones qu encuentre en todo tipo de fuentes (supuestamente) humanas online. Al hacerlo añadirá el nombre del creador de ese contenido (o su avatar) y el origen del que procede dicha perspectiva. Google también promete añadir más contexto sobre el origen de sus respuestas generadas por IA, de forma similar a cómo ChatGPT o Claude incluyen enlaces que respaldan sus respuestas.
Cansados de tanto SEO. La razón es obvia: los resultados orgánicos de Google para preguntas prácticas y subjetivas —”qué aspiradora me compro”, “cómo le curo el oído a mi perro”, “cuál es el mejor barrio para vivir en Valencia”— están dominadas por el SEO y esas técnicas optimizadas para aparecer en Google. Importa posicionar, no responder bien la pregunta. Precisamente ahí es donde Reddit, como otros foros o blogs personales tienen algo que ese contenido no suele tener: la experiencia real de alguien que estuvo en la misma situación. Google lo resume en su propio comunicado sin rodeos: “Para muchas búsquedas, la gente busca cada vez más el consejo de otras personas”.
La contradicción que Google no ha resuelto. Hay un potencial problema en esta nueva forma de concebir esas búsquedas con IA. Los AI Overviews fueron diseñados para responder preguntas directamente y así ahorrarle al usuario el trabajo de ir haciendo clic, leyendo e investigando. Ahora van a incluir perspectivas diversas e incluso contradictorias de foros y redes sociales. Así pues, ¿responderá AI Overviews la pregunta, o hará que volvamos a acudir a las fuentes para que encontremos la respuesta?. Si es lo segundo, no será muy diferente de lo que ya hacía el buscador tradicional de Google. Hay aquí un interesante desequilibrio entre “te damos la respuesta” y “te damos contexto para que encuentres la respuesta”. En cierto sentido, la decisión de Google complica las búsquedas.
Los modelos de IA son cada vez menos propensos al fallo. Los célebres casos de añadirle pegamento a la pizza son mucho menos frecuentes ahora, y a menudo los nuevos modelos presumen de una reducción significativa en las tasas de “alucinaciones” que tienen. GPT-5.5 Instant, lanzado esta semana “produjo un 52.5% menos de alucinaciones que GPT‑5.3 Instant”, indicaba OpenAI en su anuncio oficial. El problema es que esas alucinaciones son cada vez más difíciles de detectar porque estos chatbots esconden muy bien esas meteduras de pata. Que ahora el sistema incluya contenido sin verificar o validar de redes como Reddit puede ser problemático: los votos de la comunidad no siempre miden lo veraz o útil que resulta cierto hilo.
Usar Reddit tiene su aquel. Esta plataforma tiene valor precisamente porque no está optimizado para los algoritmos de Google: es caótica y contradictoria. A veces hay respuestas brillantes de la gente, pero otras hay comentarios totalmente erróneos. Cuando un usuario añade “Reddit” a su búsqueda y lee los resultados, está sopesando automáticamente qué comentarios son útiles y cuáles no. Pero ese paso desaparece si Google extrae fragmentos de esas discusiones para incluirlos en un AI Overview. Elimina ese paso de filtrado humano y presenta esas respuestas con una autoridad que quizás no deberían tener. Google tendrá muchas más dificultades que un humano de distinguir el comentario de alguien que lleva veinte años trabajando en fontanería del de alguien que hace chapuzas por afición.
El contrato en la sombra. Esta no es solo una decisión editorial o tecnológica. En 2024 Google firmó un acuerdo de 60 millones de dólares al año con Reddit para acceder a sus datos y entrenar sus modelos. No está incorporando contenido de esta red social como un servicio público: lo que está haciendo es monetizar un contrato comercial. Su mensaje de que está destacando esas “voces originales”, lo que en realidad está diciendo es que ha pagado por ese acceso privilegiado al contenido de Reddit y ahora va a aprovechar dicho acceso y a rentabilizarlo. Esos ingresos son interesantes para Reddit, sin duda, pero hay un problema: los clics.
El precedente de Stack Overflow. No hace falta especular mucho sobre lo que puede pasar porque ya ha pasado. Stack Overflow es la mayor comunidad de preguntas y respuestas técnicas de internet, pero ha perdido la mayor parte de su tráfico en dos años porque las empresas de IA empezaron a recolectar todas esas respuestas para entrenar sus modelos y luego servirlas a sus usuarios directamente. Eso provocó que los usuarios dejaran de visitar Stack Overflow y que los expertos dejaran de contestar preguntas. La calidad de los nuevos contenidos en esta red se vio claramente afectada, y quedó claor que si la IA ya te daba la respuesta sin tener que entrar en Stack Overflow, ¿para qué entrar? El peligro para Reddit es exactamente el mismo.
Google no tenía muchas alternativas. ChatGPT, Claude y Perplexity llevan tiempo capturando cuota de mercado en esas búsquedas donde la gente antes añadía “Reddit”: preguntas prácticas, recomendaciones subjetivas, o resolución de problemas específicos. Estos modelos contestan de forma directa y natural y evitan tener que navegar por resultados llenos de SEO. Incluir ese contexto y enlaces de Reddit es un intento de usar esa ventaja para ofrecer algo que los modelos de lenguaje rivales no pueden (de momento): perspectivas humanas actualizadas y verificadas por comunidades reales. La ironía es que la IA que parece saberlo todo solo aprende y mejora gracias al conocimiento y a la experiencia humana acumulada y compartida.

¿Quién paga por todo esto? Al final estamos viendo cómo Google está usando un sistema híbrido, pero la pregunta importante no es si funcionará bien o mal. La pregunta es quién paga para que la web que alimenta ese híbrido siga existiendo. Google extrae contenido de Reddit, blogs, foros y redes sociales, lo procesa con IA y lo sirve en un resumen que elimina la necesidad de visitar las fuentes originales. Y ahí entra el inevitable y peligroso círculo vicioso. Si esos sitios pierden tráfico, pierden ingresos. Si pierden ingresos, pierden la capacidad de generar el contenido que Google necesita para que sus AI Overviews funcionen. Todo un dilema aun sin solucionar.
En Xataka | Los foros de internet están desapareciendo porque ahora todo es Reddit y Discord. Y eso es preocupante
ues de anuncios individuales.
Source link
Actualidad
Si la pregunta es cuánto tiempo tenemos que usar la IA para volvernos perezosos, la respuesta es: un suspiro

Diez minutos. Es el tiempo que tarda la IA en tener un efecto negativo en nuestra habilidad para razonar y resolver problemas, o al menos eso es lo que han concluido en un nuevo estudio en el que han medido cómo el uso de asistentes de IA no solo mejora el rendimiento inmediato, sino que reduce la persistencia y empeora el desempeño cuando no tenemos acceso a la IA.
El estudio. Investigadores de Carnegie Mellon, MIT, UCLA y Oxford han publicado un experimento controlado y aleatorizado que mide el impacto del uso de IA en la capacidad de resolver problemas de forma independiente. En total participaron más de 1.200 personas en tres experimentos distintos. La conclusión de los investigadores va en la dirección de lo que hemos visto en otros estudios anteriores: usar IA potencia nuestra productividad, pero tiene un coste cognitivo.

El experimento. Se realizó un primer experimento con 354 participantes en el que debían resolver doce fracciones simples. Algunos de los participantes tenían un panel lateral con un asistente IA (GPT 5) que podían usar para resolver las operaciones. Lo curioso vino cuando se les retiró el acceso al chatbot y tuvieron que responder tres preguntas más sin la ayuda de la IA. El resultado fue que las personas que habían usado IA fallaron más en sus respuestas que el grupo de control.
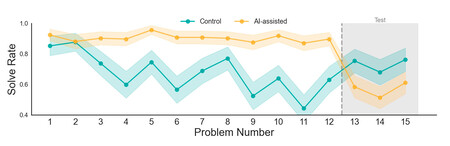
Confirmando resultados. Los investigadores hicieron un segundo experimento en el que duplicaron los participantes (667) e hicieron un pretest para medir el nivel. Además, añadieron un panel lateral “placebo” (sin IA) a los participantes del grupo control, para que no hubiera diferencias de interfaz. Los resultados volvieron a mostrar que las personas que usaban IA fallaban más que el grupo control.
Hubo un tercer experimento en el que se hicieron problemas de comprensión lectora con 201 participantes y volvió a pasar lo mismo: al quitar la IA, ese grupo es el que peor rindió.
El matiz clave. Hay un detalle importante del estudio y es que midieron cómo los participantes usaban la IA. El 61% la usó para que les diera las respuestas directamente, mientras que otros la usaron para que les diera pistas o les hiciera aclaraciones. Los resultados de este segundo grupo fueron más similares a las del grupo de control. En cambio, quien pedía las soluciones tal cual a la IA fallaron mucho más cuanto esta fue retirada. Esto sugiere lo que hemos dicho anteriormente: el efecto negativo de la IA en nuestra cognición depende en gran parte de cómo la usemos. No es lo mismo copiar respuestas sin cuestionar, que usarla como apoyo en el proceso cognitivo.
La nueva caja tonta. El miedo a que la tecnología nos vuelva tontos no es algo que haya surgido con la IA, pasó con la calculadora, ha pasado con la televisión, con los videojuegos y está pasando con los móviles. Aunque hay estudios que apuntan en esa dirección, no hay una evidencia clara de que la tecnología dañe nuestra cognición. Sin embargo, también es cierto que hasta ahora no habíamos tenido acceso a una tecnología en la que pudiéramos delegar todo nuestro pensamiento.
Imagen de portada | Xataka
ues de anuncios individuales.
Source link
-

 Deportes1 día ago
Deportes1 día agoCiclismo | Destrozan una estatua de Eddy Merckx en Bruselas
-

 Deportes2 días ago
Deportes2 días agoMundial 2026 | Aeropuerto de la CDMX luce menos preparado para la Copa del Mundo: Expertos
-

 Deportes1 día ago
Deportes1 día agoMundial 2026: Una Copa del Mundo con 48 selecciones aumentará competitividad y atraerá inversión: Infantino
-

 Deportes1 día ago
Deportes1 día agoChivas recula y permitirá asistencia de sus jugadores al Tricolor en tiempo y forma
-

 Deportes1 día ago
Deportes1 día agoMundial 2026: Jugador que no reporte hoy con la Selección no va a la Copa del Mundo: Javier Aguirre | Video
-

 Deportes1 día ago
Deportes1 día agoMundial 2026: Irán exige garantías de la FIFA para asistir a Estados Unidos
-

 Deportes1 día ago
Deportes1 día agoFIFA insiste en el mercado dinámico en medio de la polémica por los precios del Mundial
-

 Deportes2 días ago
Deportes2 días agoMundial 2026: Toluca liberará a sus seleccionados nacionales, pero aclara que actúo conforme al acuerdo y reglamento