
Escrito en ENTRETENIMIENTO el
Actualidad
A OpenAI le falta por tener un navegador propio. Google acaba de ponerle el suyo en bandeja

A Google podrían obligarle a vender su navegador Chrome. El juicio antimonopolio que se está celebrando en EEUU pasa ahora por su etapa crítica. Los jueces ya declararon que “Google es un monopolio” en el terrreno de las búsquedas y la publicidad, y ahora queda por saber cuáles serán las consecuencias para este gigante tecnológico. La exigencia de vender Chrome ya ha generado el interés de una empresa a la que ese navegador le vendría como anillo al dedo.
OpenAI estaría interesada. Nick Turley, jefe de producto en OpenAI, declaró en este proceso judicial. Al ser preguntado por si en OpenAI estarían interesados en algo así, contestó que “sí, sí lo estaríamos, así como lo estarían otras empresas”.

OpenAI quiere ser la nueva Google con su buscador. La empresa de Sam Altman lanzó en verano de 2024 SearchGPT, convertido algo después en ChatGPT Search. El buscador de IA de OpenAI es, como Perplexity, una alternativa cada vez más llamativa al buscador tradicional de Google, y con él quedaba claro que el terreno de las búsquedas es uno que OpenAI persigue dominar.
Y ahora también con un navegador con ChatGPT. Pero es que en OpenAI no solo quieren tener su propio buscador, sino también su propio navegador. En noviembre de 2024 supimos que la empresa está trabajando en un navegador propio que tendría ChatGPT integrado de forma nativa. Desarrollar un navegador es una tarea compleja, así que si Chrome se pone finalmente a la venta, adquirirlo y modificarlo sería una solución interesante para OpenAI.
Ya hemos visto cómo podría ser el Chrome de OpenAI. Cuando la empresa lanzó su buscador, lo hizo tanto con una opción integrada en chatgpt.com, como a través de una extensión para el navegador Chrome. En Xataka la probamos en aquel momento —yo la uso desde entonces— y está claro que esa combinación de Chrome+ChatGPT es realmente llamativa.

Dos de cada tres usuarios usan Chrome en todo el mundo. Fuente: Statcounter GlobalStats.
“Una experiencia increíble”. Turley destacó en su declaración que tener Chrome más integrado en OpenAI permitiría tener un producto mucho mejor. “Podríamos ofrecer una experiencia realmente increíble” si ChatGPT se integrara en Chrome, afirmó. “Tendríamos la capacidad de enseñarles a los usuarios qué podrían esperar de una experiencia con la IA como protagonista”
Chrome es demasiado dominante (y eso es genial para OpenAI). La cuota de mercado del navegador Chrome es actualmente del 66,17% según cifras de Statcounter GlobalStats. Dos de cada tres usuarios en todo el mundo lo utilizan, y solo Safari (gracias a su integración en iPhone, iPad y Mac) logra hacerle algo de sombra con un 17% de cuota. El dominio imperial de Chrome resolvería un problema fundamental para OpenAI: la distribución y difusión de ChatGPT para que llegue a más usuarios.
ChatGPT llegaría a todos lados. Es cierto que la popularidad de ChatGPT es notable, pero el propio Turley afirmaba que hay un gran problema con la distribución. Aunque tienen un acuerdo con Apple en los iPhone, no han logrado llegar a grandes acuerdos con fabricantes de dispositivos Android. Poder integrar ChatGPT en Chrome solventaría el problema de golpe y porrazo y permitiría que su chatbot estuviese “preinstalado” en cientos de millones de dispositivos.

OpenAI pide libre competencia…. El directivo de OpenAI también habló de cómo algunos de sus competidores
“controlan los puntos de acceso a cómo la gente descubre productos, incluido el nuestro. La gente los descubre a través de un navegador o de una tienda de aplicaciones. Tener capacidad de elección real impulsa la competitividad. Los usuarios deberían tener la capacidad de elegir”.
… por ahora. Es, por supuesto, un discurso esperable de alguien que de momento no tiene un monopolio y que quiere intentar competir con quienes sí lo tienen. Es evidente que Turley se refería a Apple y a Google, las dos empresas que dominan el mercado y la distribución de productos. Antes lo hizo Microsoft y aprovechó por ejemplo para convertir a su navegador Internet Explorer en el absoluto dominador del mercado. Lo hizo hasta que la UE le obligó a ofrecer otras opciones y hasta que Firefox y finalmente Chrome ganaron esa partida.
Un juicio determinante. Tras el proceso legal que declaró que Google es un monopolio en el terreno de las búsquedas y que concluyó hace unos meses, ahora se está celebrando la fase que en EEUU llaman “remedies”, y que se centra en las medidas que debe tomar la corte judicial para solucionar el problema. Esta parte del proceso durará unas tres semanas, y el futuro de Google puede verse impactado de forma enorme dependiendo de las decisiones que se tomen.
Una posibilidad remota. Sea como fuere, nada está ni mucho menos decidido aún, y se tendría que producir una carambola importante para que OpenAI acabara haciéndose con Chrome. Para empezar, la justicia estadounidense tendría que obligar a Google a vender definitivamente Chrome. Google probablemente apelaría, lo que alargaría que la sentencia se hiciese efectiva. Y para entonces OpenAI quizás haya lanzado su propio navegador, pero lo que es seguro es que Chrome también le interesaría a otras muchas empresas, y habría una lucha y una puja espectacular para hacerse con este desarrollo.
Imagen | AS Photography | TechCrunch
ues de anuncios individuales.
Source link
Continue Reading
Actualidad
Adobe se presenta como defensora de los creadores en la era de la IA. Una demanda alega que usó libros con derechos de autor

Adobe ha construido parte de su estrategia en inteligencia artificial sobre una bandera muy reconocible: proteger a los creadores en un momento de cambio profundo. Mientras otras tecnológicas acumulaban críticas por el origen de sus datos, la compañía se presentaba como una alternativa responsable. Esa posición se enfrenta ahora a una demanda que pone el foco en el entrenamiento de uno de sus modelos y en el uso de obras con derechos de autor. El caso no es una anomalía, sino un reflejo de una pregunta que la industria todavía no ha logrado responder con claridad.
La demanda se presentó el martes en el Tribunal Federal del Distrito Norte de California y adopta la forma de una acción colectiva propuesta. Una autora llamada Elizabeth Lyon acusa a Adobe de haber utilizado libros protegidos por derechos de autor, incluidos los suyos, para entrenar modelos de IA de la compañía, con SlimLM como elemento central del caso, sin contar con permiso. Según la documentación judicial, esas obras habrían formado parte del proceso de entrenamiento de sistemas diseñados para responder a instrucciones humanas. Lyon afirma actuar en nombre de otros titulares de derechos que se encontrarían en una situación similar.
El gran debate sobre los datos que entrenan a la IA
Para entender por qué este tipo de litigios se repite cada vez con más frecuencia, conviene detenerse un momento en cómo funciona la inteligencia artificial actual. Más allá de las aplicaciones visibles, desde chatbots hasta generadores de imágenes, existen modelos subyacentes que actúan como el núcleo del sistema y aprenden a partir de enormes volúmenes de datos. En términos generales, disponer de más datos puede mejorar el rendimiento, aunque no es el único factor. El problema aparece cuando surge la pregunta clave sobre el origen de esa información y las condiciones bajo las que se ha utilizado.
El modelo señalado en la demanda no es Firefly, el sistema creativo más conocido de Adobe, sino SlimLM, una familia de modelos de lenguaje de menor tamaño pensada para tareas concretas. Estos modelos están diseñados para asistir a los usuarios en funciones relacionadas con documentos, especialmente en dispositivos móviles. No se trata de una IA orientada a la generación creativa a gran escala, sino de un sistema que opera en segundo plano. Esa diferencia es relevante porque muestra que el debate sobre los datos de entrenamiento no se limita a las aplicaciones más visibles.
Según la demanda, el conflicto no estaría en SlimLM como producto final, sino en los datos empleados durante su fase de entrenamiento. Adobe ha explicado que estos modelos se preentrenaron con SlimPajama-627B, un conjunto de datos de código abierto publicado por Cerebras en junio de 2023. El escrito judicial sostiene que SlimPajama deriva de RedPajama, otro dataset ampliamente utilizado en la industria, y que este a su vez incorpora Books3, una colección masiva de libros protegidos por derechos de autor. Esa cadena es la que, según la demandante, habría permitido la inclusión de obras sin autorización.

Hasta ahora, la narrativa pública de Adobe sobre inteligencia artificial se ha articulado principalmente alrededor de Firefly, un producto claramente identificado con el respeto a los creadores y el uso de contenidos con licencia. La empresa ha defendido que estos modelos se entrenaron con contenido con licencia, como Adobe Stock, y material de dominio público, y ha acompañado ese mensaje con programas de compensación para colaboradores de Adobe Stock. La demanda, sin embargo, no se dirige a ese frente visible, sino, como decimos, a SlimLM, un modelo más discreto, integrado en tareas de asistencia y sin una presencia comercial directa. Esa separación resulta clave para entender el alcance real del caso.
El procedimiento contra Adobe se enmarca en un contexto más amplio de litigios en Estados Unidos relacionados con el entrenamiento de modelos de IA. En los últimos años, autores y otros titulares de derechos han llevado a los tribunales a empresas tecnológicas como OpenAIo Anthropic, con demandas que alegan el uso de obras protegidas sin autorización. Algunos de estos procesos siguen abiertos y otros han terminado en acuerdos millonarios. Ese escenario explica por qué cada nuevo caso se interpreta como un paso más en la delimitación legal del uso de datos en la inteligencia artificial.

Por ahora, el caso se encuentra en una fase inicial y deja abiertas muchas incógnitas. La demandante solicita una compensación económica no especificada y plantea la acción en nombre de otros posibles afectados, mientras que Adobe no respondió a la solicitud de comentarios de Reuters. Será el proceso judicial el que determine si la demanda prospera, se archiva o deriva en un acuerdo. Más allá de su desenlace concreto, el litigio vuelve a poner el foco en una cuestión que sigue sin resolverse del todo: cómo equilibrar el avance de la IA con los derechos de quienes crean los contenidos de los que aprende.
Imágenes | Rubaitul Azad | Adobe
ues de anuncios individuales.
Source link
Actualidad
Kevin Spacey regresará a la televisión con una miniserie de comedia italiana que se estrenará este diciembre


EFE.- El actor estadounidense Kevin Spacey regresará a la pantalla pequeña el próximo 26 de diciembre con la serie ”Minimarket”, una comedia italiana que se estrenará en el servicio de streaming por la televisión pública RAI.
Esta será su primera serie en televisión desde su salida de la famosa ”House of Cards” en 2017, cuando fue despedido a raíz de las acusaciones de abuso sexual que surgieron en su contra.
El actor de 66 años de edad y ganador de dos Premios Óscar por ”American Beauty” (1999) y ”The Usual Suspects” (1995), era uno de los actores más respetados de Hollywood hasta que llegó la primera acusación contra él.
El actor fue posteriormente absuelto de nueve cargos de delitos sexuales en el Reino Unido y obtuvo una victoria en una demanda civil en Estados Unidos relacionada con una insinuación sexual no deseada ocurrida en 1986.
En la nueva serie, ”Minimarket”, Kevin Spacey interpretará a un mentor poco convencional de Manlio Viganò (Filippo Laganà), un joven que trabaja en una pequeña tienda de comestibles en Roma y sueña con convertirse en una estrella de televisión.
El personaje del veterano actor es su amigo imaginario y mentor, que aparece como una presencia inquebrantable, ejerciendo como la “conciencia artística” del joven.
La relación entre ambos tiene un tono cómico: mientras que Spacey aporta su vasta experiencia de los sets de Hollywood, el ingenuo Manlio no es consciente de que está siendo guiado por un ganador del Óscar.
La serie, de diez episodios y que mezcla humor con momentos surrealistas, se estrenará en RaiPlay el 26 de diciembre con los primeros cinco episodios, y la segunda parte de la temporada llegará hasta el 9 de enero.
Desde el estallido del escándalo por las acusaciones de abusos de Kevin Spacey ha participado en pocos proyectos, pero ha rodado tres películas en los últimos años: ”1780” (2025), ”Gore” que finalmente se canceló y ”The Awakening”, que se estrenará en los próximos meses.
ues de anuncios individuales.
Source link
Actualidad
Un adolescente descubrió el virus ‘Málaga’ y acabó fundando VirusTotal. El enigma que queda es el mismo desde 1992: quién lo programó

Bernardo Quintero (@bquintero) tenía 14 años y su primer PC, un Amstrad PC-1512, acababa de llegar a casa. Era 1987, y el cofundador de VirusTotal quedó entusiasmado por aquella máquina que le permitía explotar su curiosidad informática. Su pasatiempo acabó siendo intentar burlar los sistemas de protección anticopia de algunos juegos, y en esas estaba un día cuando repente ocurrió algo.
Una bolita blanca se movía por su pantalla. Por sí sola. Sin que él hubiera hecho nada.
Pronto descubrió que aquello era un virus informático. Uno que acabó estudiando para saber cómo poder detectarlo y eliminarlo. Lo consiguió, y durante los tres años siguientes acabó mejorando su primer antivirus, una herramienta que permitía reconocer y erradicar siete virus distintos con los que se había encontrado.

No parecía que aquel proyecto fuera a ir mucho más allá, y Quintero comenzó sus estudios de Informática en la Escuela Universitaria Politécnica de Málaga. En una de las primeras clases, un profesor preguntó si alguien quería subir nota con algún proyecto de programación en Pascal. Él se apuntó, y al hablar con el profesor, éste le preguntó si había hecho algún proyecto anterior.
“Bueno, sí”, contestó. “Un programa de contabilidad, utilidades de disco, un antivirus…”. El profesor le cortó. “¿Has dicho antivirus?”. Al contestar afirmativamente, el profesor le pidió que le acompañara a su despacho. Allí le mostró cómo todo el departamento de informática había sido infectado por un virus que los antivirus no reconocían.
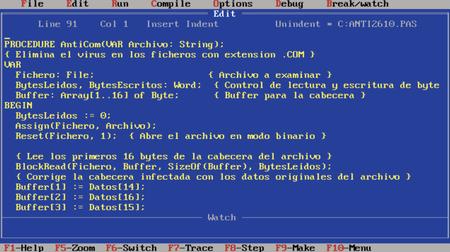
Fragmento del código en Turbo Pascal 5.5 del antivirus que desarrolló Bernardo Quintero para eliminar el virus “Málaga-2610” (1992). Fuente: Bernardo Quintero.
Quintero pronto detectó dónde podía estar el problema y se fue a casa con un disco infectado para trabajar en un antivirus. Le costó más de lo que pensaba, pero tras unas horas logró saber cómo detectarlo y borrarlo. Aquello le sirvió para aprobar la asignatura, pero además acabó siendo la semilla definitiva del proyecto profesional que acabaría con la fundación de Virus Total.

Lo cuenta todo con más detalle en su novela, ‘Infectado‘, que publicó a principos de año y en la que narra esos comienzos y cómo eso acabó llevándole a crear VirusTotal, la empresa malagueña que luego acabaría siendo comprada por Google.

Aquel virus de su facultad se llamaba “Málaga”, y Quintero pasó años sin volver a prestarle demasiada atención. Entonces, hace tres años, este experto publicó un mensaje en Twitter (X) para intentar resolver el misterio de quién lo habría creado.
Ya entonces descubrió que según varias fuentes el virus se había creado en la Escuela Politécnica de Informática. El objetivo, contaba entonces, no era sacar a la luz el nombre, sino charlar con esa persona y recordar aquellos tiempos. No consiguió desvelar el misterio, y aquel misterio quedó de nuevo sin resolver.
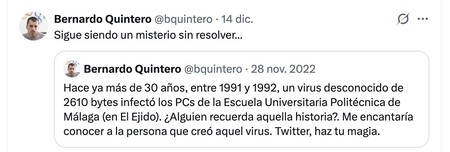
Pero Bernardo Quintero nunca se olvidó de aquello y volvió a la carga con un nuevo intento hace unos días. Tras publicar primero un mensaje en X, al día siguiente publicó un resumen de aquella historia en LinkedIn, y pidió ayuda en esa publicación para intentar resolver el misterio de una vez.
Nos pusimos en contacto con él, y nos contaba cómo mientras que en el pasado se había enfocado en descubrir cómo infectaba y en crear la herramienta de desinfección, nunca trató de saber quién había creado el virus “Málaga”. Pero nos decía que “ahora, al verlo con nuevos ojos, he visto un par de detalles interesantes y he descubierto la motivación”.
De hecho, añade que gracias a esos mensajes en X y LinkedIn “me han llegado historias de varias personas que estudiaron esos años en la Politécnica de Málaga y que creen conocer al autor”. De esos candidatos, explica, “he descartado a 3 o 4, pero hay uno que casa muy bien con los nuevos datos que tengo”.
El misterio parece estar cerca de resolverse. “Solo me falta despejar una incógnita para confirmar al autor. Y si se confirma, hay una bonita y triste historia que merecerá la pena ser contada”. Todo apunta por tanto a que al fin se sabrá quién fue el autor de aquel virus, y Quintero ha prometido contar más detalles estos días. Estaremos atentos.
Imagen | Mika Baumeister
En Xataka | El ordenador con más malware del mundo: así es MICE, el reto de Bernardo Quintero y VirusTotal
ues de anuncios individuales.
Source link
-
Deportes2 días ago
Mundial 2026: Confirman partido amistoso Panamá vs. México el 22 de enero
-

 Actualidad2 días ago
Actualidad2 días agouna evolución lógica en un contexto donde las fintech cada vez ofrecen más servicios
-

 Actualidad2 días ago
Actualidad2 días agoBoeing ha salido al rescate
-

 Actualidad1 día ago
Actualidad1 día agoEl turrón se las prometía felices en su búsqueda de sabores imposibles. Hasta que las almendras y huevos dispararon su precio
-

 Tecnologia2 días ago
Tecnologia2 días ago¿Cuáles son los famosos más influyentes por publicación en Instagram?
-

 Actualidad1 día ago
Actualidad1 día agoRosalía sabe que estamos en la era post-woke y lo está reflejando en cada movimiento
-

 Actualidad1 día ago
Actualidad1 día agoMédico ligado a la muerte de Matthew Perry no estará en prisión: le dan ocho meses de arresto domiciliario
-
Deportes2 días ago
Obliga justicia gala al PSG a pagar salarios atrasados a Mbappé