
Escrito en ENTRETENIMIENTO el
Actualidad
Uber ha ha gastado en cuatro meses su presupuesto anual para IA porque la IA nos está convirtiendo en adictos a ella

El CTO de Uber, Praveen Neppalli Naga, explicaba recientemente cómo su empresa decidió desplegar Claude Code entre sus 5.000 ingenieros. La adopción de la herramienta se disparó del 32% al 84% en un mes, y todos ellos comenzaron a usarla tanto que Uber se encontró con un problema: el coste real pasó de los 500 a los 2.000 dólares mensuales por programador, lo que destrozó las previsiones de gasto de la compañía: en cuatro meses se gastaron todo el presupuesto anual para implantar IA en la empresa. Bienvenidos al fin de las subvenciones de IA.
Microsoft también controlará el gasto. El caso de Uber no es un hecho aislado. Microsoft cuenta con recursos de computación prácticamente ilimitados con Azure. Sin embargo, ha tomado la decisión de retirar las licencias internas de Claude Code a sus desarrolladores de la división Experiences + Devices. El motivo es doble: en primer lugar, quieren frenar el gasto operativo antes del cierre de su año fiscal. En segundo, quieren forzar el uso de sus propias herramientas con GitHub Copilot como claro protagonista.
GitHub acaba con su tarifa plana. Esta empresa, propiedad de Microsoft, también se quiere preparar para el futuro, y desde el 1 de junio de 2026 todos los planes de GitHub Copilot abandonan su opción de “tarifa plana” para pasar a un modelo de facturación basado en el uso. El precio base de la suscripción se mantiene, pero se convierte en “créditos de IA” que se irán consumiendo a medida que se vaya usando el modelo. Si los desarrolladores usan de forma intensiva GitHub Copilot, los créditos se agotarán rápidamente y el sistema se detendrá a no ser que paguemos extra por poder seguir trabajando. En GitHub señalaban que “cobrar una tarifa plana por agentes autónomos ya no es sostenible”.
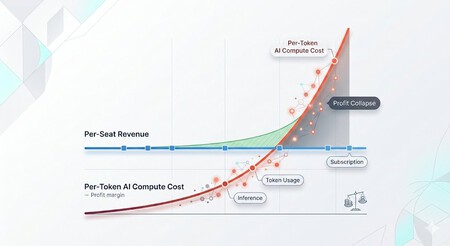
Fuente: Hedgie (X).
El gráfico que lo explica todo. Un usuario de X llamado Hedgie avisaba de que esto es solo el principio y añadía una útil imagen para comprender lo que está pasando.
- El modelo de software tradicional SaaS (Software as a Service) funciona en línea recta. Pagas una cuota mensual y los costes del servidor apenas varían tanto si usas esa app o servicio diez minutos o diez horas: el margen de beneficio es predecible, y la carga asumible. Es lo que pasa con las “tarifas planas” a servicios de streaming por ejemplo. Que tú veas más o menos horas de Netflix no supone una gran diferencia para la infraestructura de Netflix.
- Pero la IA agéntica opera bajo una curva exponencial. Como se ve en la imagen, cuando un agente de IA de programación como Claude Code empieza a funcionar, puede llegar a utilizar miles o incluso millones de llamadas a la API del proveedor (en este caso, Anthropic) para recibir, procesar y demver millones de tokens.
- Las tarifas planas que ofrecían ChatGPT Plus o Claude Pro son adecuadas para un uso conversacional de la IA, pero los agentes de IA devoran tokens y el consumo se dispara. Por eso Anthropic, OpenAI y otras ponen límites a sus tarifas planas e incluso prohíben su uso para tareas agénticas (como las que proporciona OpenClaw o los agentes de programación). Ahí piden que pagues por uso con la API, y eso dispara los costes.
Encrucijada. Esta situación coloca a empresas como OpenAI, Anthropic y Google en un dilema. Si sus clientes (como Uber) empiezan a recortar el uso de la IA para proteger sus presupuestos, los ingresos de dichas empresas pueden verse frenados y eso afectará a sus valoraciones. La otra potencial solución es bajar precios artificialmente para mantener a esos clientes contentos, pero eso supone absorber pérdidas operativas importantes que perjudicarían su rentabilidad.
Dependencia y adicción de la IA. Estas empresas se están dando cuenta de que utilizar la IA puede ser realmente provechoso, pero también caro. El modelo de negocio de Anthropic o de OpenAI no es nuevo, y hemos visto ese patrón en el pasado. Una empresa lanza un producto o servicio, a menudo gratis o muy barato, pero tras conseguir un volumen de usuarios suficiente acaba cambiando sus condiciones para cobrarte cada vez más por ese producto o servicio.
Ya ha pasado. Tenemos un buen ejemplo en Google Fotos o en los servicios de streaming, que nos atraparon para luego exprimirnos con cuotas mensuales cada vez más altas. Con la IA el panorama es el mismo: atraparnos ahora con costes reducidos para luego capar el servicio gratuito y hacernos pagar si queremos aprovecharla de verdad. Siempre habrá alternativas como usar modelos locales u optar por plataformas más baratas, por supuesto, pero para quienes ofrecen los modelos y prestaciones más avanzados la estrategia es clara.
En Xataka | Los resultados económicos de Nvidia son sencillamente mareantes. Y aún no ha vendido un solo chip en China
ues de anuncios individuales.
Source link
Continue Reading
Actualidad
Presentamos Xataka Life, nuestro nuevo canal de YouTube sobre domótica y tecnología para transformar tu hogar

2026 viene cargado de novedades en Xataka. Si hace apenas un par de meses anunciamos el lanzamiento de Xataka Xtra, hoy traemos un nuevo proyecto llamado Xataka Life. En esta casa llevamos año hablado de domótica, conectividad y dispositivos para el hogar, una categoría cada vez más relevante en el mundo de la tecnología y que, a través de Xataka Life, exploraremos en forma de vídeo.
Porque Xataka Life es, precisamente, un canal de YouTube. Uno en el que trataremos temas relacionados con el hogar, la domotización, el ahorro y productos que, poco a poco, han ido encontrando un hueco en las casas de cada vez más personas. Hablamos de dispositivos de iluminación, freidoras de aire o robots aspiradores, por mencionar solo algunos.
¿Qué cambia en el canal de YouTube de Xataka? Absolutamente nada. Este canal seguirá funcionado como hasta ahora con los contenidos que ya publicamos. Xataka Life es un espacio adicional que nos permite ahondar en un tema tan complejo, pero al mismo tiempo tan apasionante e interesante, como es la tecnología para el hogar.
Como no podría ser de otra manera, Xataka Life se expande más allá del formato largo de YouTube, por lo que también podrás contenido corto en @xatakalife en Instagram. Si te gusta cómo suena, te invitamos a seguirnos en Instagram y, por supuesto, a suscribirte a Xataka Life en YouTube.
¡Seguimos!
ues de anuncios individuales.
Source link
Actualidad
Retrato del boxeo infantil en el barrio de Tepito gana Palma de Oro de cortometraje en Cannes


EFE.- “Me gustaría poder dedicarle esto al barrio de Tepito, de México”, aseguró este sábado el realizador argentino Federico Luis, en declaraciones a la agencia EFE tras ganar en el Festival de Cine de Cannes la Palma de Oro de mejor cortometraje por “Para los contrincantes”, en el que retrató el mundo del boxeo infantil en ese distrito de la capital mexicana.
Luis se refirió al barrio de Tepito como un lugar “donde nos recibieron y donde muchas veces suele haber una idea equivocada sobre cómo uno puede ser recibido ahí”, expresó, y en especial manifestó que le gustaría dar un abrazo a Damián, el pequeño que protagoniza su cortometraje.
En “Para los contrincantes”, Luis hace un conmovedor retrato del mundo del boxeo infantil en México, un mundo que descubrió en compañía del escritor mexicano Mario Bellatin.
Para ello, siguió con su cámara a un joven peleador real de Tepito, Damián López, que sueña con convertirse en campeón.
La idea de este corto que mezcla la ficción con el documental surgió prácticamente por casualidad, durante la preparación del que será el próximo largometraje de ficción de Luis, que versará sobre un entrenador de perros y que parte de un personaje de la obra de Bellatin.
Cine a pesar de todo
Federico Luis, quien en 2024 fue el gran ganador de la Semana de la Crítica —sección paralela del Festival de Cannes— con su ópera prima “Simón de la montaña” aseguró que los creadores independientes de su país van a seguir trabajando, incluso a pesar de la falta de apoyo institucional desde la llegada al gobierno de Javier Milei.

Señaló que “en las situaciones en las que las cosas se vuelven más difíciles pasa muchísimo, y no es esto la excepción, que aparecen formas muy sorprendentes de cómo inventar una nueva forma de hacer“, apuntó.
“Eso es algo que en Argentina pasa y va a seguir pasando, independientemente de cualquier gobierno”, opinó Luis, quien nació en la ciudad de Buenos Aires en 1990.
Para el director, al mundo del cine argentino le gustaría no depender de empresas multinacionales, sino que haya un instituto de cine “fuerte” que permita que surjan nuevos realizadores y también que conserve el patrimonio histórico nacional, algo que ha visto en Cannes, donde se proyectó la versión restaurada de “La casa del ángel” de Leopoldo Torre Nilsson (1957).
“Que la gente que ya viene teniendo un camino en el cine se pueda expresar libremente y no tenga que pedirle permiso a nadie que esté atravesado por un interés que no sea el cine”, desea Federico Luis.
ues de anuncios individuales.
Source link
Actualidad
DeepSeek es bueno, bonito y muy barato. Y sobre todo, el arma para crear una industria china de hardware independiente de Nvidia

La llegada de DeepSeek-V4-Pro no ha causado tanto revuelo como la que causó DeepSeek R1 hace un año y medio, pero puede que estemos ante un modelo aún más importante. Si aquella versión le descubrió al mundo que China estaba avanzando de forma espectacular en esta carrera, esta otra está comenzando a permitir vislumbrar otra cosa más interesante. Lo que ve la mayoría es un modelo muy decente y sobre todo “tirado de precio”. Lo que esconde la empresa es otra cosa más importante: lograr la independencia de Nvidia y el hardware de EEUU.
Qué ha pasado. El pasado viernes los responsables de DeepSeek anunciaban algo sorprendente: su oferta promocional con un recorte de precio del 75% para usar su modelo DeepSeek-V4-Pro se mantendrá de forma permanente. Eso hace que este modelo, ofrezca prestaciones muy decentes (pero no excepcionales) por un precio realmente bajo:
|
1M tokens de entrada |
1M tokens salida |
|
|---|---|---|
|
DeepSeek-V4-Pro |
0,435 |
0,87 |
|
GPT-5.5 |
5 |
30 |
|
Opus 4.7 |
5 |
25 |
|
Gemini 3.5 Flash |
1,5 |
9 |
Bueno, bonito y muy barato. Es cierto que el rendimiento de DeepSeek-V4-Pro es inferior al de los modelos rivales de OpenAI, Anthropic o Google. Las pruebas de Artificial Analysis indican que el modelo de DeepSeek está a muy buen nivel, pero es además mucho más económico que sus competidores. Eso es especialmente relevante para tareas agénticas que consumen muchísimos tokens y que con este modelo se vuelven accesibles y muy asequibles.
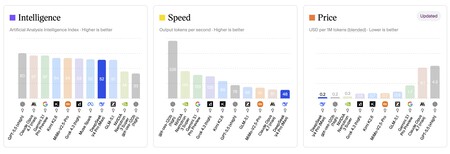
Según Artificial Analysis, DeepSeek se acerca al rendimiento de los mejores modelos de la industria, y aunque es más lento en sus respuestas, es también mucho más barato que los modelos frontera de OpenAI, Anthropic o Google.
Una estrategia diferente. ¿Cómo va a ganar dinero esta empresa? No tiene planes de suscripción como su competencia local (GLM, Kimi) o la occidental (ChatGPT Plus, Claude Pro). Tampoco tiene modelos de voz o de imagen. No cuenta con un agente de IA para programación que compita con Claude Code. Publica los pesos abiertos de sus modelos y comparte sus innovaciones técnicas con la industria (y con sus competidores). Para quien sigue de cerca la empresa y estas decisiones la estrategia está clara. El objetivo de DeepSeek no es ganar la carrera de modelos de IA. Su objetivo es construir una industria china de hardware de IA que no dependa de Nvidia ni de TSMC… y cobrar su parte en ese proceso.
Independencia hardware. China tiene un problema estructural en esta carrera de la IA: las sanciones y vetos impuestos por EEUU hacen que no pueda acceder a los chips más avanzados ni a la fotolitografía UVE de ASML. Y como China no puede de momento competir en términos de capacidad de cómputo, lo que están haciendo sus empresas es lograr que sus modelos de IA necesiten menos capacidad de cómputo para lograr resultados similares.
Arquitecturas eficientes. Las arquitecturas Mixture of Experts (MoE) y Multi-head Latent Attention (MLA) son dos armas clave en esta estrategia. La primera ya existía pero fue adaptada por DeepSeek para su modelo: con ella solo se activan parte de los parámetros totales del modelo para responder la consulta sin perder precisión. Lo que hace MLA es comprimir la información de atención (la llamada KV Cache) con la que el modelo mantiene el contexto de una conversación, reduciéndola en un 90%. Ambas técnicas permiten reducir la necesidad de usar memorias HBM de alta velocidad, algo que es también llamativo de cara a desvelar la probable estrategia de DeepSeek.
La importancia de la KV Cache. Como explica el analista GDP en X, ese uso de MLA permite que para un millón de tokens, DeepSeek-V4-Pro solo necesite 5,48 GB de memoria HBM. Competidores como Zhipo AI, que desarrollan GLM 5, necesitan 60 GB para lo mismo, mientras que Qwen 3, de Alibaba, necesita 89 GB. Esta ventaja permite a DeepSeek ofrecer precios mucho más bajos para obtener rendimientos similares a los de su competencia, pero además hace que los modelos de DeepSeek puedan ejecutarse en chips de memoria chinos que no pueden competir en velocidad con módulos HBM.
Adiós HBM, hola NAND y SSD. Estas innovaciones abren la puerta al uso de memorias NAND e incluso unidades SSD para procesar estos datos, y ahí entra en escena YMTC, un fabricante chino de memorias Flash que se está convirtiendo poco a poco en un gigante global. También CXMT, que fabrica memorias DRAM, se convierte aquí en una alternativa y la razón es igualmente interesante: DeepSeek presentó un módulo de búsqueda de memoria en LLMs llamado Engram que está destinado también a evitar la excesiva dependencia de memorias HBM.

Cómo esquivar el monopolio CUDA. Nvidia sigue teniendo en CUDA un elemento fundamental para mantener su dominio del mercado, pero aquí DeepSeek también ha planteado una alternativa. Se llama Tile Kernels y se trata de unos núcleos software creados con TileLang (una variante de Python para este campo) que permiten gobernar chips de IA avanzados (GPUs).
Huawei como aliado invisible. Los responsables de Huawei indicaron recientemente que sus nuevos supernodos Ascend AI soportan completamente los modelos DeepSeek v4. Precisamente eso aporta otra ventaja fundamental a la empresa, que evita así (al menos en parte) la dependencia total de uso de chips de Nvidia y se prepara para poder fortalecer aún más la relevancia de Huawei en un mercado en que hasta hace poco la empresa de Jensen Huang era reina y señora.
Modelos abiertos para atraer a la industria hardware. Las empresas de EEUU siguen manteniendo sus modelos cerrados y propietarios, pero DeepSeek es una de las muchas startups chinas que los publican con pesos abiertos. Con ello lo que pretenden ella y las demás es no solo atraer a desarrolladores y usuarios de IA, sino crear un ecosistema hardware que adopte estas arquitecturas. DeepSeek invita a sus rivales a usar técnicas como MoE o MLA precisamente para que todos estos avances se conviertan en un estándar de facto y los fabricantes de hardware también los adopten e integren de forma optimizada en sus diseños.
Una ronda de 10.000 millones para avanzar. La empresa está además preparando una ronda de financiación en la que pretenden levantar 10.000 millones de dólares y con la que consiguirían una valoración de entre 45.000 y 50.000 millones de dólares. Aún lejos de las mastodónticas valoraciones de OpenAI o Anthropic (cercanas ya al billón de dólares) pero desde luego extraordinarias para una startup china. Con ese dinero tendrán muchas más opciones de seguir reforzando esta estrategia.
ues de anuncios individuales.
Source link
-

 Deportes2 días ago
Deportes2 días agoMéxico vence en amistoso a Ghana, que jugó sin sus principales figuras
-

 Musica2 días ago
Musica2 días agoMonsieur Periné anuncia nueva gira internacional; llegará a América y Europa
-

 Musica2 días ago
Musica2 días agoAlejandro Markovhich en coma: Estas son las enfermedades que ha enfrentado el músico
-

 Tecnologia2 días ago
Tecnologia2 días agograban reuniones, crean notas automáticas y traducen conversaciones en tiempo real
-

 Musica2 días ago
Musica2 días agoNo importa que lo hagas mal: hacer ESTO reduce tus niveles de estrés sin importar tu talento
-

 Actualidad2 días ago
Actualidad2 días agoHay una ciudad medieval en Alemania construida en un cráter de meteorito. Sus muros esconden 72.000 toneladas de diamantes
-

 Musica1 día ago
Musica1 día agoZapopan convierte sus plazas en escenario musical para celebrar la quinta Fiesta de la Música
-

 Actualidad2 días ago
Actualidad2 días agoEstilista de Fátima Bosch fue detenido en Cannes por agresión, YosStop hablará de su paso por prisión en un libro y Karla Souza estrenará la cinta “México 86”